Contrastive Learning for Prompt-Based Few-Shot Language Learners
Jian, Y., Gao, C., & Vosoughi, S. (2022). Contrastive learning for prompt-based few-shot language learners. arXiv preprint arXiv:2205.01308.
요약: 대조학습이 무엇인지, 라벨링된 데이터가 적을 때 대조학습을 어떻게 활용할 수 있는지 이 두 가지가 핵심.
Contrastive learning에 대한 전체적인 설명
대조학습(Contrastive learning)은 비지도 학습 및 지도 학습 방법 중 하나로, 데이터 포인트 간의 유사성 및 차이를 학습하는 데 초점을 맞춥니다. 이 기법은 고차원 데이터를 저차원으로 효과적으로 표현하도록 도움을 줍니다. 대조학습은 비슷한 예시들을 가까이 끌어모으고 동시에 서로 다른 예시들을 멀리 떨어뜨리는 방식으로 작동합니다. 이를 통해 모델은 특징 공간에서 유사한 데이터 포인트를 임베딩하여 분류, 클러스터링 등의 작업을 수행할 수 있습니다.
<Contrastive Learning for Prompt-Based Few-Shot Language Learners>
새로운 지도 대조학습 프레임워크와 프롬프트를 사용한 효과적인 증강 방법을 제안
이 프레임워크는 프롬프트 기반 언어 학습자의 성능을 향상시키는 데 도움이 됩니다. 그러나 제한사항으로는 SupCon이 클래스 수준에서 예시를 묶기 때문에 분류 작업에만 적용되며, 큰 배치 크기가 필요한 인배치 대조 손실로 인해 큰 GPU 메모리가 필요하다는 점이 있습니다. 이 논문의 방법론은 15개의 퓨샷 작업에서 최근 연구를 능가하는 결과를 보였습니다.
<논문 요약>
Abstract
A contrastive learning framework for better fine-tuning of moderately-sized models using limited examples.
The proposed supervised contrastive framework clusters inputs from the same class under different augmented “views” and repels those from different classes. By combining a contrastive loss with the standard masked language modeling loss, the method shows improvements over state-of-the-art methods in 15 language tasks. The framework is broadly applicable with minimal assumptions on the task or base model.
제한된 예제를 사용하여 중간 크기의 모델을 더 잘 세밀 조정하기 위한 대조 학습 프레임워크를 제시합니다. 제안된 감독 대조 프레임워크는 *서로 다른 증강된 “뷰” 하에서 동일한 클래스의 입력을 클러스터링하고 다른 클래스의 입력을 거부합니다. 대조 손실과 표준 마스크 언어 모델링 손실을 결합함으로써, 이 방법은 15개의 언어 작업(언어 모델의 성능을 평가하기 위한 다양한 자연 언어 처리(NLP) 작업들: 기계 번역, 감정 분석, 질문 답변, 개체명 인식, 요약 등)에서 최첨단 방법론을 개선할 수 있습니다. 이 프레임워크는 작업이나 기본 모델에 대한 최소한의 가정으로 널리 적용할 수 있습니다.
대조손실(Contrastive loss): 대조 학습에서 사용되는 손실 함수로, 같은 클래스의 데이터는 가까운 공간에 위치하게 하고 다른 클래스의 데이터는 멀리 위치하게 하는 것을 목표로 합니다. 예를 들어, 이미지 인식에서 같은 개체의 다른 이미지들은 가까운 공간에 위치하도록 하고, 다른 개체의 이미지들은 떨어져 위치하도록 합니다.
표준마스크 언어모델링 손실(Standard masked LM loss): 마스크된 토큰이 주어진 문맥에 기반하여 예측되는 방식으로 작동하는 언어 모델에서 사용되는 손실 함수입니다. 예를 들어, “나는 오늘 [MASK]을 먹었다” 문장에서 [MASK] 부분에 적절한 단어를 예측하는 것이 목표
Introduction
This paper introduces Supervised Contrastive Learning (SupCon) for prompt-based few-shot language learners, with an effective data augmentation method using prompts. By creating multiple “views” of a single example using different templates and demonstrations, the model can construct diverse input texts that are consistent and complete. SupCon helps the model obtain additional supervision at the feature space, which is essential when given few labeled examples. 이 논문은 프롬프트 기반 소수샷 언어 학습자를 위한 감독 대조 학습(SupCon)을 소개하며, 프롬프트를 사용한 효과적인 데이터 증강 방법을 제공합니다. 서로 다른 템플릿과 데모를 사용하여 단일 예제의 여러 “뷰”를 생성함으로써 모델은 일관되고 완전한 다양한 입력 텍스트를 구성할 수 있습니다. SupCon은 특징 공간에서 추가적인 지도를 얻는 데 도움이 되며, 이는 레이블이 지정된 예제가 적을 때 중요합니다.
- <소개>요약: 프롬프트 기반 소수샷 언어 학습자를 위한 감독 대조 학습(SupCon)과 프롬프트를 이용한 효과적인 데이터 증강 방법을 소개한다. 다양한 템플릿과 데모를 사용하여 일관되고 완전한 입력 텍스트를 만들어내고, 특징 공간에서 추가적인 지도를 얻는 데 도움이 된다.
프롬프트 기반: 프롬프트란 언어 모델에게 입력을 제공하는 방식입니다.
예를 들어, 언어 모델에게 질문에 대한 답변을 생성하도록 하는 것입니다. 프롬프트는 모델이 문제를 이해하고 올바른 예측을 내놓을 수 있도록 도와줍니다. 이 방식은 모델이 사전 훈련과 미세 조정 단계 사이의 차이를 줄이는데 도움이 됩니다.소수샷(적은 예제를 가지고 학습): 소수샷 학습이란, 적은 양의 레이블이 있는 학습 데이터를 사용하여 모델을 훈련하는 방법입니다. 이 방식은 새로운 작업에 대해 충분한 양의 레이블이 있는 데이터를 구하기 어려운 경우에 유용합니다. 소수샷 학습을 통해, 모델은 제한된 데이터를 가지고도 높은 성능을 달성할 수 있습니다.
프롬프트 기반 소수샷 언어 학습자의 경우, 데이터 증강을 위해 서로 다른 템플릿과 데모를 사용하여 단일 예제의 여러 “뷰”를 생성할 수 있습니다.
예를 들어, 영화 리뷰를 분류하는 작업에서 주어진 리뷰가 “긍정적”이라는 레이블을 가지고 있다고 가정해보겠습니다. 이를 위해, 우리는 다양한 템플릿과 데모를 사용하여 아래와 같은 여러 “뷰”를 생성할 수 있습니다.원래 리뷰: “이 영화는 정말 재미있고 감동적이다.”
템플릿 A: “이 작품은 {blank}이다.”
데모 A: “이 작품은 정말 멋진 걸작이다.”
생성된 입력 A: “이 영화는 정말 재미있고 감동적이다. 이 작품은 정말 멋진 걸작이다. 이 작품은 {blank}이다.”템플릿 B: “이 영화는 정말 {blank}하다.”
데모 B: “이 영화는 정말 환상적이다.”
생성된 입력 B: “이 영화는 정말 재미있고 감동적이다. 이 영화는 정말 환상적이다. 이 영화는 정말 {blank}하다.”위의 예제에서 입력 A와 입력 B는 동일한 리뷰를 기반으로 하지만, 서로 다른 템플릿과 데모를 사용하여 다양한 “뷰”를 생성하였습니다. 이렇게 생성된 다양한 “뷰”를 통해 모델은 각 입력에 대한 더 나은 예측을 할 수 있게 됩니다. 이러한 방법은 특히 레이블이 있는 예제가 적은 상황에서 효과적입니다.
Related Work
This excerpt discusses how meta-learning and data augmentation often address few-shot learning. Prompt-based fine-tuning, inspired by GPT-3’s in-context learning, has recently become dominant in NLP. The paper proposes an augmentation method for prompt-based fine-tuning that outperforms EDA, as used in contrastive learning for few-shot semi-supervised intent classification. Supervised Contrastive Loss (SupCon) is a form of contrastive learning that clusters two augmented batches at the class level in the feature space. 메타 학습 및 데이터 증강을 통해 소수샷 학습이 어떻게 처리되는지에 대해 설명합니다. GPT-3의 인-컨텍스트 학습에서 영감을 받은 프롬프트 기반 파인 튜닝은 최근 NLP에서 지배적이게 되었습니다. 본 논문에서는 프롬프트 기반 파인 튜닝을 위한 증강 방법을 제안하며, EDA를 사용한 몇몇샷 반지도 의도 분류에 대한 대조 학습보다 우수한 성능을 보여줍니다. 지도 대조 손실(SupCon)은 특징 공간에서 클래스 수준에서 두 개의 증강 배치를 클러스터링하는 대조 학습의 특수한 형태입니다.
<요약> 소수샷 학습에 메타 학습과 데이터 증강이 자주 사용된다고 설명합니다. GPT-3의 인-컨텍스트 학습에서 영감을 얻은 프롬프트 기반 파인 튜닝은 최근 NLP에서 주류가 되었습니다. 본 연구에서는 프롬프트 기반 파인 튜닝을 위해 EDA보다 성능이 뛰어난 증강 방법을 제안하고 있습니다. 지도 대조 손실(SupCon)은 특징 공간에서 클래스 수준에서 두 개의 증강 배치를 클러스터링하는 대조 학습의 한 형태입니다.
Method
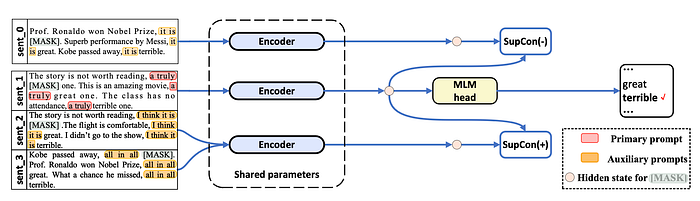
The authors introduce a fine-tuning method for few-shot learning using prompts and demonstrations. Their method incorporates language-based supervised contrastive loss (LSupCon) and the masked language modelling (MLM) loss used in LM-BFF. The total loss for their method is Ltotal = LMLM + LSupCon (Equation 3). This requires an additional forward and backward pass, increasing computational cost by 1.5 times. The method is described in Algorithm 1. 프롬프트와 데모를 사용한 몇 번의 샷 학습을 위한 미세조정 방법을 소개합니다. 그들의 방법은 LM-BFF에서 사용된 마스크된 언어 모델링(MLM) 손실 외에도 언어 기반 감독 대비 손실(LSupCon)을 포함합니다. 그들의 방법에 대한 전체 손실은 Ltotal = LMLM + LSupCon (수식 3)입니다. 이는 추가적인 순전파 및 역전파가 필요하며, 계산 비용이 1.5배 증가합니다.
<요약> 프롬프트와 데모를 사용한 몇 번의 샷 학습을 위한 미세조정 방법(알고리즘 1)을 도입합니다. 이 방법은 마스크된 언어 모델링 손실 외에도 언어 기반 감독 대비 손실을 포함하며, 전체 손실은 Ltotal = LMLM + LSupCon (수식 3)입니다. 추가 순전파 및 역전파가 필요해 계산 비용이 1.5배 증가합니다.
Algorithm 1
# 1: 최대 학습 스텝(Max_Step)을 1000으로 설정합니다.
max_step = 1000
# 2: LM은 사전 훈련된 언어 모델을 나타냅니다.
lm = LanguageModel()
# 3: Train_Set은 훈련 데이터 세트를 의미합니다.
train_set = TrainingSet()
# 4: Sample은 무작위로 샘플링하는 함수를 나타냅니다.
sample = random_sampling_function()
# 5: Concatenate는 두 문자열을 연결하는 함수를 의미합니다.
concatenate = concatenate_function()
# 6: CE는 Cross Entropy 손실 함수를 나타냅니다.
ce = CrossEntropyLoss()
# 7: SupCon은 감독 대비 손실 함수를 의미합니다.
supcon = SupervisedContrastiveLoss()
# 8: i가 Max_Step에 도달할 때까지 반복합니다.
for i in range(max_step):
# 9: sent와 y를 훈련 데이터 세트에서 무작위로 샘플링합니다.
sent, y = sample(train_set)
# 10: demo1을 훈련 데이터 세트에서 무작위로 샘플링합니다.
demo1 = sample(train_set)
# 11: demo2를 훈련 데이터 세트에서 무작위로 샘플링합니다.
demo2 = sample(train_set)
# 12: input1은 sent와 demo1을 연결한 문자열입니다.
input1 = concatenate(sent, demo1)
# 13: input2는 sent와 demo2를 연결한 문자열입니다.
input2 = concatenate(sent, demo2)
# ◃ Learning from MLM Loss
# 14: output1은 언어 모델을 사용하여 input1에서 생성된 출력입니다.
output1 = lm(input1)
# 15: LMLM은 output1과 y 사이의 Cross Entropy 손실을 계산합니다.
lmlm = ce(output1, y)
# 16: LMLM의 그래디언트를 역전파합니다.
lmlm.backward()
# 17: 옵티마이저로 가중치를 업데이트합니다.
optimizer.step()
# ◃ Learning from SupCon Loss
# 18: output2는 언어 모델을 사용하여 input2에서 생성된 출력입니다.
output2 = lm(input2)
# 19: LSupCon은 output1과 output2 사이의 감독 대비 손실을 계산합니다.
lsupcon = supcon(output1, output2)
# 20: LSupCon의 그래디언트를 역전파합니다.
lsupcon.backward()
# 21: 옵티마이저로 가중치를 업데이트합니다.
optimizer.step()
# 22: 반복문 종료