Varifocal Question Generation for Fact-checking
Abstract
The paper presents Varifocal, a method for fact-checking that generates questions based on different focal points within a given claim, outperforming previous work on a fact-checking question generation dataset on a wide range of automatic evaluation metrics. This is achieved by generating questions based on different spans of the claim and its metadata, such as its source and date, rather than assuming the answer is known and typically contained in a given passage. The method generates more relevant and informative questions and has the potential for generating sets of clarification questions for product descriptions. 본 논문에서는 주어진 주장의 서로 다른 초점에서(claim과 해당 메타데이터의 서지 및 날짜 등) 질문을 생성하는 Varifocal 방법을 제시한다. 이는 답변이 주어진 문서를 입력으로 가정하는 기존의 방법과는 달리, 검증 중인 주장을 검증하기 위한 문서를 찾아야 하는 상황에서 효과적으로 동작한다. Varifocal은 폭넓은 자동 평가 지표에서 과거 연구들보다 우수한 성능을 보이며, 수작업 평가에서도 더욱 관련성이 높고 유용한 질문들을 생성할 수 있다는 것을 보여준다. 이러한 초점들을 이용하여 제품 설명에 대한 명확화 질문 세트를 생성하는 등의 가능성도 제시된다.
Introduction
The article discusses the growing need for fact-checking due to the abundance of information online, and how automation can be used to accelerate the fact-checking process. The use of questions and answers has been found to be an effective way of conveying fact-checks. However, previous work on question generation assumes that the answer is known, which is not always the case in fact-checking. In response to this, the article proposes an approach called Varifocal that generates questions for claim verification using different focal points from the claim and its metadata. The approach was evaluated on the QABriefs dataset using automatic metrics and a human evaluation and was found to generate more intelligible, clear, relevant, and informative questions than other systems. 이 논문은 인터넷 상의 정보가 많아지면서 사실 검증의 필요성이 증가하고 자동화를 통해 사실 검증 과정을 가속화하는 방법에 대해 논의하고 있다. 질문과 답변의 사용이 사실 검증을 전달하는 효과적인 방법임이 입증되었다. 그러나, 이전의 질문 생성 작업은 대답이 이미 알려진 경우를 가정하고 있어 사실 검증에는 적합하지 않다. 이에 대응하여, 이 논문에서는 Varifocal이라는 방법을 제안하며, 이는 요약에 대한 다양한 초점과 메타데이터를 활용하여 질문을 생성하는 방식이다. 이 방법은 QABriefs 데이터셋에서 자동적으로 평가하고, 사람들로부터 인간적인 평가도 받았다. 결과적으로 Varifocal은 다른 시스템보다 더 쉽게 이해할 수 있는, 명확하고, 관련성이 높으며, 정보성이 높은 질문을 생성할 수 있었다. 또한, Varifocal은 Amazon 제품 설명에 대한 요약 질문 생성에도 적용되어 단일 질문 생성 방법과 경쟁할 만큼의 성과를 보여주었다.
Related Work
Previous work on question generation for fact-checking is mainly focused on the QABriefs dataset proposed by Fan et al. (2020), which includes claims with manually annotated question-answer pairs. The QABriefer model was introduced to generate a set of questions based on the claim and retrieve answers from the web. However, they only evaluated their questions using BLEU scores, and human evaluation was not conducted. Other related work includes Saeidi et al. (2018), who introduced a dataset containing real-world policies, fictional scenarios, and dialogues, but it differs from fact-checking as the questions have to have a yes or no answer, and the information to be searched is known in advance. Majumder et al. (2021) proposed a method to generate clarification questions, which is not directly applicable to fact-checking. The standard sequence-to-sequence architecture is typically used in question-generation approaches, but answer-aware approaches are not useful for fact-checking. 팩트 체크를 위한 질문 생성에 대한 이전 연구는 Fan et al. (2020)이 제안한 QABriefs 데이터 세트에 초점을 맞추고 있다. 이 데이터 세트에는 수동으로 주석이 달린 질문-답변 쌍이 포함되어 있다. QABriefer 모델은 주장을 기반으로 질문 세트를 생성하고 웹에서 답변을 검색한다. 그러나, BLEU 점수만을 사용하여 질문의 품질을 평가하였으며, 인간 평가는 수행하지 않았다. 관련된 다른 연구는 Saeidi et al. (2018)이 소개한 정책, 허구적 시나리오 및 대화를 포함한 데이터 세트로 구성된다. 하지만 질문은 예/아니오로 대답할 수 있어야 하며, 검색해야 할 정보가 미리 알려져 있는 차이점이 있다. Majumder et al. (2021)는 명확화 질문을 생성하기 위한 방법을 제안했으나, 직접적으로 팩트 체크에 적용할 수 없다. 질문 생성 접근 방식에서는 표준 시퀀스-투-시퀀스 아키텍처가 일반적으로 사용되며, 답변 인식 접근 방식은 팩트 체크에 유용하지 않다.
Varifocal Question Generation
Varifocal is an approach that generates multiple questions per claim based on different aspects of the claim, called focal points. It consists of three components: a focal point extractor, a question generator, and a re-ranker. Focal points are contiguous spans from the claim and metadata elements, which can be useful in question generation. The metadata is incorporated using a template. Varifocal은 클레임의 다양한 측면에 따라 여러 질문을 생성하는 접근 방식으로, 포컬 포인트라는 텍스트 스팬에 기반합니다. Varifocal은 포컬 포인트 추출기, 질문 생성기, 재랭커로 구성됩니다. 포컬 포인트는 클레임에서 연속된 텍스트 스팬과 메타데이터 요소로 구성되며, 질문 생성에 유용합니다. 메타데이터는 템플릿을 사용하여 통합됩니다.

1)Focal Point Extractor
In the evidence retrieval step, we retrieve documents that are relevant to the claim using TF-IDF cosine similarity. We represent the claim and each document as a bag of words and compute the cosine similarity between them. We keep the top K documents according to their cosine similarity scores. 증거 검색 단계에서는 TF-IDF 코사인 유사도를 사용하여 주장과 관련된 문서를 검색합니다. 주장과 각 문서를 단어 가방으로 나타내고 이들 간의 코사인 유사도를 계산합니다. 코사인 유사도 점수에 따라 상위 K개의 문서를 유지합니다.
2)Question Generation
The Question Generation component takes a claim and its focal points as input and generates a set of questions. The model generates a question $\hat{q}{i}$ for each focal point $f{i}$ in the claim $c$. The generator is trained to use focal points instead of answers to generate the questions, which are autoregressively generated based on the transformer-based encoding of $c$ concatenated to $f_{i}$. 질문 생성 구성 요소는 주장과 주요 포인트를 입력으로 받아 질문 세트를 생성합니다. 모델은 클레임 $c$에서 각 주요 포인트 $f_{i}$마다 질문 $\hat{q}{i}$를 생성합니다. 생성기는 대답 대신 주요 포인트를 사용하여 질문을 생성하도록 훈련되며, $c$와 $f{i}$를 병합한 transformer 기반 인코딩을 기반으로 자동 회귀적으로 생성됩니다. 여기서 *’자동회귀’는 이전 단계에서 생성된 출력을 다음 입력으로 사용하는 생성 모델의 방식을 의미합니다. 따라서 모델이 이전 출력을 참고하여 새로운 출력을 생성하고 이 과정을 반복하여 전체 시퀀스를 생성합니다. 이는 주로 자연어 생성 작업에서 사용되는 기법 중 하나임.
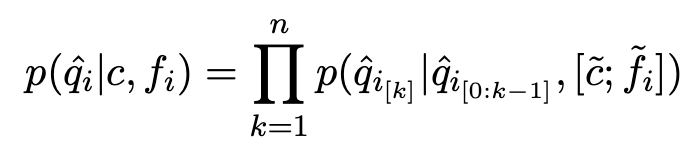
3)Re-ranking
After generating question candidates for each focal point, the re-ranker removes duplicates and almost identical questions based on a BLEU score threshold of 0.8. Then, a regression model scores the remaining questions and assigns a real number score to each candidate based on how similar it is expected to be to one of the gold questions. 중복되거나 거의 동일한 질문을 제거하고, 남은 질문 후보들에 대해 회귀 모델을 사용하여 각 후보에 대한 실수값 점수를 할당한다. 후보 질문이 골드 질문 중 하나와 유사할수록 높은 점수를 받는다.
4)Training
To train the question generation model, focal points paired with the questions that they led to generate are needed. However, most question-generation datasets have questions paired with answers instead of focal points. Therefore, cosine similarity is used to match extracted focal points fi ∈ F with the gold answers during training. Then, each answer (and associated question) is greedily matched with the highest-scoring focal point. 질문 생성 모델을 훈련하기 위해서는 초점 포인트와 해당 포인트에서 생성된 질문이 필요하다. 하지만 대부분의 질문 생성 데이터셋은 포인트 대신 답변과 질문이 연결되어 있다. 따라서, 훈련 중에 추출된 초점 포인트 fi와 골드 답변 aj를 코사인 유사도로 매칭한다. 매칭 후, 각 답변(및 관련된 질문)을 가장 높은 점수를 받은 초점 포인트와 매칭시킨다
Objective Function
Given a claim c, the re-ranker g is trained to predict the similarity score that a question would have with the best matching question from the gold standard. Therefore, it considers the maximum sentence similarity of each of the generated questions qˆ and the gold standard ones qj ∈ Q, with Q the set of gold questions associated with c. The objective function is expressed. re-ranker는 클레임 c에 대해, 생성된 질문 qˆ와 골드 표준 질문 집합 Q 중 최대 문장 유사성을 고려하여 유사도 점수를 예측하도록 훈련된다. 목적 함수는 이러한 점수를 기준으로 표현된다.
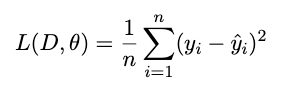
Results
5.1 자동 평가: Varifocal 시스템은 BART와 SQuAD보다 약 4 ROUGE-1 포인트, >4 METEOR 포인트 높은 성능을 보여주었습니다. 또한, TER 기반의 오류율도 낮았습니다. SQuAD는 QABriefs 데이터셋에서 훈련되지 않았음에도 BART를 약간 능가했습니다. 이는 질문 생성에 초점 포인트를 사용했기 때문입니다.

5.2 인간 평가: 평가자들은 총 250개의 질문을 평가했습니다. 이 평가에서 Varifocal과 Varifocal+Meta가 평균적으로 가장 좋은 질문을 생성하며, 특히 관련성과 정보성이 높았습니다. BART 모델은 높은 정보성을 가진 팩트 체크 질문 생성에 실패했습니다.
5.3 아마존 데이터셋에서의 평가: 아마존 데이터셋에서 Varifocal 및 초점 포인트의 잠재력을 평가하기 위해 실험을 진행했습니다. 제품 설명만을 가지고 질문을 생성할 때 Varifocal이 13.2의 BLEU-4 점수를 달성했습니다. 이 결과는 다른 연구에서 사용한 기준선을 능가했습니다.
결론적으로, Varifocal 시스템은 자동 평가와 인간 평가에서 높은 성능을 보여주었으며, 팩트 체크 질문 생성에 뛰어난 결과를 보였습니다. 또한 아마존 데이터셋에서의 실험을 통해, Varifocal이 다양한 도메인에서도 유용하게 사용될 수 있음을 보여주었습니다.
